Sequence modeling is a critical area of machine learning, encompassing applications such as reinforcement learning, time series forecasting, and event prediction. These models are designed to handle data where the order of inputs is important, making them essential for tasks such as robotics, financial forecasting, and medical diagnostics. Traditionally, recurrent neural networks (RNNs) have been used for their ability to efficiently process sequential data despite their limitations in parallel processing.
Rapid advances in machine learning have highlighted the limitations of existing models, particularly in resource-constrained environments. Transformers, known for their exceptional performance and ability to leverage GPU parallelism, are resource-intensive, making them unsuitable for low-resource environments such as mobile and embedded devices. The main challenge lies in their quadratic memory and computational requirements, which hamper their deployment in scenarios with limited computational resources.
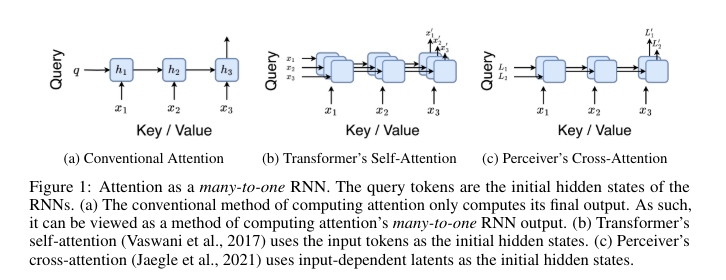
Existing works include several attention-based models and methods. Transformers, despite their excellent performance, are resource intensive. Approximations such as RWKV, RetNet, and Linear Transformer offer attention linearizations for efficiency, but have limitations in terms of token bias. Attention can be computed recurrently, as shown by Rabe and Staats, and softmax-based attention can be reformulated as an RNN. Efficient algorithms for computing prefix scans, such as those of Hillis and Steele, provide fundamental techniques for improving attention mechanisms in sequence modeling. However, these techniques must fully take into account the inherent resource intensity, especially in applications involving long sequences, such as climate data analysis and economic forecasting. This has led to exploring alternative methods to maintain performance while being more resource efficient.
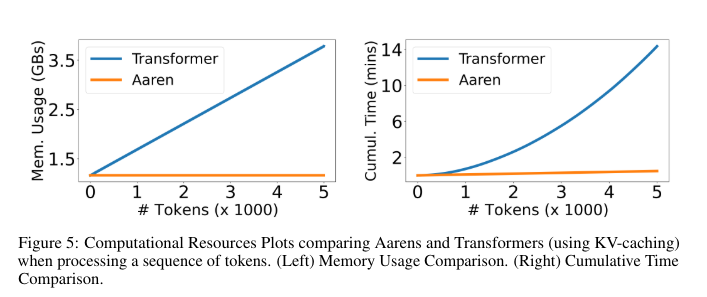
Mila and Borealis AI researchers introduced Attention as a Recurrent Neural Network (Aaren), a new method that reinterprets the attention mechanism as a form of RNN. This innovative approach maintains the benefits of parallel training of Transformers while allowing efficient updates with new tokens. Unlike traditional RNNs, which process data sequentially and struggle to be scalable, Aaren leverages the parallel prefix parsing algorithm to compute attention outputs more efficiently, handling sequential data with requirements of constant memory. This makes Aaren particularly suitable for low-resource environments where IT efficiency is paramount.
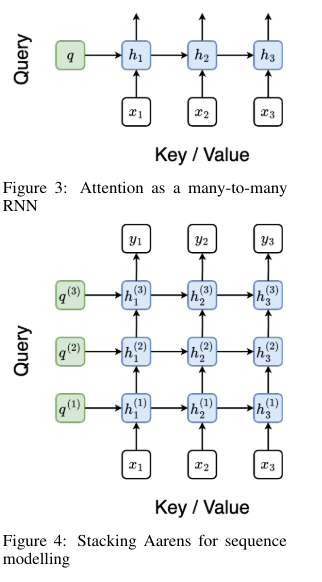
In detail, Aaren works by considering the attention mechanism as a many-to-one RNN. Conventional attention methods calculate their outputs in parallel, requiring linear memory over the number of tokens. However, Aaren introduces a new method for computing attention in the form of a many-to-many RNN, significantly reducing memory usage. This is achieved through a parallel prefix parsing algorithm that allows Aaren to process multiple context tokens simultaneously while efficiently updating its state. Attention outputs are calculated using a series of associative operations, ensuring that memory and computational load remain constant, regardless of sequence length.
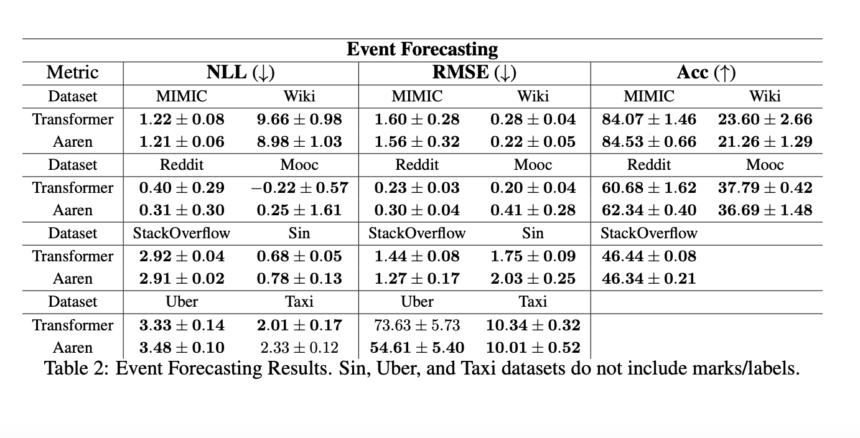
Aaren's performance has been empirically validated in various tasks, demonstrating its effectiveness and robustness. In reinforcement learning tasks, Aaren was tested on 12 datasets from the D4RL benchmark, including environments like HalfCheetah, Ant, Hopper, and Walker. The results showed that Aaren achieved competitive performance with Transformers, delivering scores such as 42.16 ± 1.89 for Medium datasets in the HalfCheetah environment. This effectiveness extends to event prediction, where Aaren has been evaluated on eight popular datasets. For example, on the Reddit dataset, Aaren achieved a negative log-likelihood (NLL) of 0.31 ± 0.30, showing comparable performance to Transformers but with reduced computational overhead.
Aaren has been tested on eight real-world datasets in time series forecasting, including Weather, Exchange, Traffic, and ECL. For the weather dataset, Aaren obtained a root mean square error (MSE) of 0.24 ± 0.01 and a mean absolute error (MAE) of 0.25 ± 0.01 for a forecast length of 192, demonstrating the ability to effectively manage time series data. Similarly, Aaren achieved comparable results to Transformers on ten datasets from the UEA Time Series Classification Archive in time series classification, demonstrating its versatility and effectiveness.
In conclusion, Aaren significantly advances sequence modeling for resource-constrained environments. By combining the parallel training capabilities of Transformers with the efficient updating mechanism of RNNs, Aaren provides a balanced solution that maintains high performance while being computationally efficient. This makes it an ideal choice for applications in low-resource environments where traditional models are insufficient.
Check Paper. All credit for this research goes to the researchers of this project. Also don’t forget to follow us on Twitter. Join our Telegram channel, Discord ChannelAnd LinkedIn Groops.
If you like our work, you will love our bulletin..
Don't forget to join our 43,000+ ML subreddit | Also see our AI Events Platform
Nikhil is an intern consultant at Marktechpost. He is pursuing an integrated dual degree in materials from the Indian Institute of Technology, Kharagpur. Nikhil is an AI/ML enthusiast who is always looking for applications in areas such as biomaterials and biomedical science. With a strong background in materials science, he explores new advances and creates opportunities for contribution.