Speaker diarization, an essential process in audio analysis, segments an audio file based on the identity of the speaker. This article explores PyAnnote's integration of Hugging Face for speaker diarization with Amazon SageMaker asynchronous endpoints.
We provide a comprehensive guide on how to deploy speaker segmentation and clustering solutions using SageMaker on the AWS Cloud. You can use this solution for applications dealing with multi-speaker audio recordings (more than 100).
Solution Overview
Amazon Transcription is the go-to service for speaker diarization in AWS. However, for unsupported languages, you can use other models (in our case, PyAnnote) which will be deployed to SageMaker for inference. For short audio files where inference takes up to 60 seconds, you can use real-time inference. For more than 60 seconds, asynchronous inference must be used. The added benefit of asynchronous inference is the cost savings achieved by automatically scaling the number of instances to zero when there are no queries to process.
Cuddly face is a popular open source platform for machine learning (ML) models. AWS and Hugging Face have a Partnership which enables seamless integration through SageMaker with a set of AWS Deep Learning (DLC) containers for training and inference in PyTorch or TensorFlow, as well as Hugging Face estimators and predictors for SageMaker's Python SDK. SageMaker features and capabilities help developers and data scientists easily get started with natural language processing (NLP) on AWS.
Integrating this solution involves using Hugging Face's pre-trained speaker diarization model using the PyAnnote Library. PyAnnote is an open source toolkit written in Python for speaker diarization. This model, trained on the audio data sample, allows for efficient speaker partitioning in audio files. The model is deployed to SageMaker as an asynchronous endpoint configuration, providing efficient and scalable processing of diarization tasks.
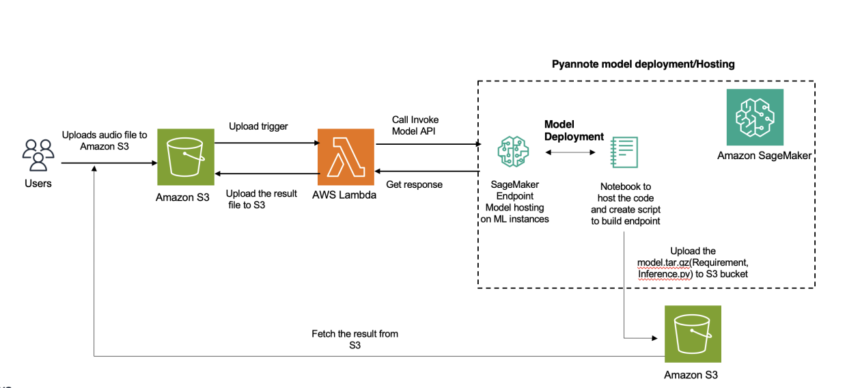
The following diagram illustrates the solution architecture.
For this article we are using the following audio file.
Stereo or multichannel audio files are automatically mixed to mono by channel averaging. Audio files sampled at a different frequency are automatically resampled to 16 kHz when loading.
Make sure the AWS account has a service quota to host a SageMaker endpoint for an ml.g5.2xlarge instance.
Create a template function to access PyAnnote speaker diarization from Hugging Face
You can use the Hugging Face Hub to access your desired pre-workout. PyAnnote speaker diarization model. You use the same script to upload the template file when creating the SageMaker endpoint.
See the following code:
from PyAnnote.audio import Pipeline
def model_fn(model_dir):
# Load the model from the specified model directory
model = Pipeline.from_pretrained(
"PyAnnote/speaker-diarization-3.1",
use_auth_token="Replace-with-the-Hugging-face-auth-token")
return model
Package model code
Prepare essential files like inference.py, which contains the inference code:
%%writefile model/code/inference.py
from PyAnnote.audio import Pipeline
import subprocess
import boto3
from urllib.parse import urlparse
import pandas as pd
from io import StringIO
import os
import torch
def model_fn(model_dir):
# Load the model from the specified model directory
model = Pipeline.from_pretrained(
"PyAnnote/speaker-diarization-3.1",
use_auth_token="hf_oBxxxxxxxxxxxx)
return model
def diarization_from_s3(model, s3_file, language=None):
s3 = boto3.client("s3")
o = urlparse(s3_file, allow_fragments=False)
bucket = o.netloc
key = o.path.lstrip("/")
s3.download_file(bucket, key, "tmp.wav")
result = model("tmp.wav")
data = {}
for turn, _, speaker in result.itertracks(yield_label=True):
data(turn) = (turn.start, turn.end, speaker)
data_df = pd.DataFrame(data.values(), columns=("start", "end", "speaker"))
print(data_df.shape)
result = data_df.to_json(orient="split")
return result
def predict_fn(data, model):
s3_file = data.pop("s3_file")
language = data.pop("language", None)
result = diarization_from_s3(model, s3_file, language)
return {
"diarization_from_s3": result
}
Prepare a requirements.txt file, which contains the Python libraries required to run the inference:
with open("model/code/requirements.txt", "w") as f:
f.write("transformers==4.25.1\n")
f.write("boto3\n")
f.write("PyAnnote.audio\n")
f.write("soundfile\n")
f.write("librosa\n")
f.write("onnxruntime\n")
f.write("wget\n")
f.write("pandas")
Finally, compress the inference.py and requirejs.txt and save it as model.tar.gz:
Configure a SageMaker template
Define a SageMaker model resource by specifying the image URI and model data location in Amazon Simple Storage Service (S3) and SageMaker role:
import sagemaker
import boto3
sess = sagemaker.Session()
sagemaker_session_bucket = None
if sagemaker_session_bucket is None and sess is not None:
sagemaker_session_bucket = sess.default_bucket()
try:
role = sagemaker.get_execution_role()
except ValueError:
iam = boto3.client("iam")
role = iam.get_role(RoleName="sagemaker_execution_role")("Role")("Arn")
sess = sagemaker.Session(default_bucket=sagemaker_session_bucket)
print(f"sagemaker role arn: {role}")
print(f"sagemaker bucket: {sess.default_bucket()}")
print(f"sagemaker session region: {sess.boto_region_name}")
Upload the model to Amazon S3
Download the compressed PyAnnote Hugging Face template file to an S3 bucket:
Configure an asynchronous endpoint to deploy the model to SageMaker using the provided asynchronous inference configuration:
from sagemaker.huggingface.model import HuggingFaceModel
from sagemaker.async_inference.async_inference_config import AsyncInferenceConfig
from sagemaker.s3 import s3_path_join
from sagemaker.utils import name_from_base
async_endpoint_name = name_from_base("custom-asyc")
# create Hugging Face Model Class
huggingface_model = HuggingFaceModel(
model_data=s3_location, # path to your model and script
role=role, # iam role with permissions to create an Endpoint
transformers_version="4.17", # transformers version used
pytorch_version="1.10", # pytorch version used
py_version="py38", # python version used
)
# create async endpoint configuration
async_config = AsyncInferenceConfig(
output_path=s3_path_join(
"s3://", sagemaker_session_bucket, "async_inference/output"
), # Where our results will be stored
# Add nofitication SNS if needed
notification_config={
# "SuccessTopic": "PUT YOUR SUCCESS SNS TOPIC ARN",
# "ErrorTopic": "PUT YOUR ERROR SNS TOPIC ARN",
}, # Notification configuration
)
env = {"MODEL_SERVER_WORKERS": "2"}
# deploy the endpoint endpoint
async_predictor = huggingface_model.deploy(
initial_instance_count=1,
instance_type="ml.xx",
async_inference_config=async_config,
endpoint_name=async_endpoint_name,
env=env,
)
Test the endpoint
Evaluate endpoint functionality by sending an audio file for diarization and retrieving the JSON output stored in the specified S3 output path:
# Replace with a path to audio object in S3
from sagemaker.async_inference import WaiterConfig
res = async_predictor.predict_async(data=data)
print(f"Response output path: {res.output_path}")
print("Start Polling to get response:")
config = WaiterConfig(
max_attempts=10, # number of attempts
delay=10# time in seconds to wait between attempts
)
res.get_result(config)
#import waiterconfig
To deploy this solution on a large scale, we suggest using AWS Lambda, Amazon Simple Notification Service (Amazon SNS), or Amazon Simple Queue Service (AmazonSQS). These services are designed for scalability, event-driven architectures, and efficient resource utilization. They can help decouple the asynchronous inference process from result processing, allowing you to scale each component independently and handle bursts of inference requests more efficiently.
Results
The model output is stored in s3://sagemaker-xxxx /async_inference/output/. The result shows that the audio recording has been segmented into three columns:
Start (start time in seconds)
End (end time in seconds)
Speaker (speaker label)
The following code shows an example of our results:
You can set a scaling policy to zero by setting MinCapacity to 0; asynchronous inference allows you to automatically go to zero without any request. You don't need to delete the endpoint, it Balance from scratch when it is needed again, thereby reducing costs when not in use. See the following code:
# Common class representing application autoscaling for SageMaker
client = boto3.client('application-autoscaling')
# This is the format in which application autoscaling references the endpoint
resource_id='endpoint/' + <endpoint_name> + '/variant/' + <'variant1'>
# Define and register your endpoint variant
response = client.register_scalable_target(
ServiceNamespace="sagemaker",
ResourceId=resource_id,
ScalableDimension='sagemaker:variant:DesiredInstanceCount', # The number of EC2 instances for your Amazon SageMaker model endpoint variant.
MinCapacity=0,
MaxCapacity=5
)
If you want to remove the endpoint, use the following code:
The solution can efficiently handle multiple or large audio files.
This example uses a single instance for demonstration. If you want to use this solution for hundreds or thousands of videos and use an asynchronous endpoint to process multiple instances, you can use a autoscaling policy, designed for a large number of source documents. Autoscaling dynamically adjusts the number of instances provisioned for a template in response to changes in your workload.
The solution optimizes resources and reduces system load by separating long-running tasks from real-time inference.
Conclusion
In this article, we proposed a simple approach to deploy the Hugging Face speaker diarization model on SageMaker using Python scripts. Using an asynchronous endpoint provides an efficient and scalable way to provide diarization predictions as a service, thereby responding to concurrent requests transparently.
Get started with asynchronous speaker diarization for your audio projects today. Contact us in the comments if you have any questions about getting your own asynchronous diarization endpoint up and running.
about the authors
Sanjay Tiwary is a specialized AI/ML solutions architect who spends his time working with strategic clients to define business requirements, deliver L300 sessions around specific use cases, and design AI/ML applications and services that are scalable, reliable and efficient. He helped launch and scale the AI/ML-powered Amazon SageMaker service and implemented several proofs of concept using Amazon AI services. He also developed the advanced analytics platform as part of the digital transformation journey.
Kiran Challapalli is a commercial developer of deep technologies with the public sector AWS. He has over 8 years of experience in AI/ML and 23 years of overall software development and sales experience. Kiran helps public sector enterprises across India explore and co-create cloud-based solutions that use AI, ML and generative AI technologies, including large language models.
Sign Up For Daily Newsletter
Be keep up! Get the latest breaking news delivered straight to your inbox.
By signing up, you agree to our Terms of Use and acknowledge the data practices in our Privacy Policy. You may unsubscribe at any time.



 Sanjay Tiwary is a specialized AI/ML solutions architect who spends his time working with strategic clients to define business requirements, deliver L300 sessions around specific use cases, and design AI/ML applications and services that are scalable, reliable and efficient. He helped launch and scale the AI/ML-powered Amazon SageMaker service and implemented several proofs of concept using Amazon AI services. He also developed the advanced analytics platform as part of the digital transformation journey.
Sanjay Tiwary is a specialized AI/ML solutions architect who spends his time working with strategic clients to define business requirements, deliver L300 sessions around specific use cases, and design AI/ML applications and services that are scalable, reliable and efficient. He helped launch and scale the AI/ML-powered Amazon SageMaker service and implemented several proofs of concept using Amazon AI services. He also developed the advanced analytics platform as part of the digital transformation journey. Kiran Challapalli is a commercial developer of deep technologies with the public sector AWS. He has over 8 years of experience in AI/ML and 23 years of overall software development and sales experience. Kiran helps public sector enterprises across India explore and co-create cloud-based solutions that use AI, ML and generative AI technologies, including large language models.
Kiran Challapalli is a commercial developer of deep technologies with the public sector AWS. He has over 8 years of experience in AI/ML and 23 years of overall software development and sales experience. Kiran helps public sector enterprises across India explore and co-create cloud-based solutions that use AI, ML and generative AI technologies, including large language models.