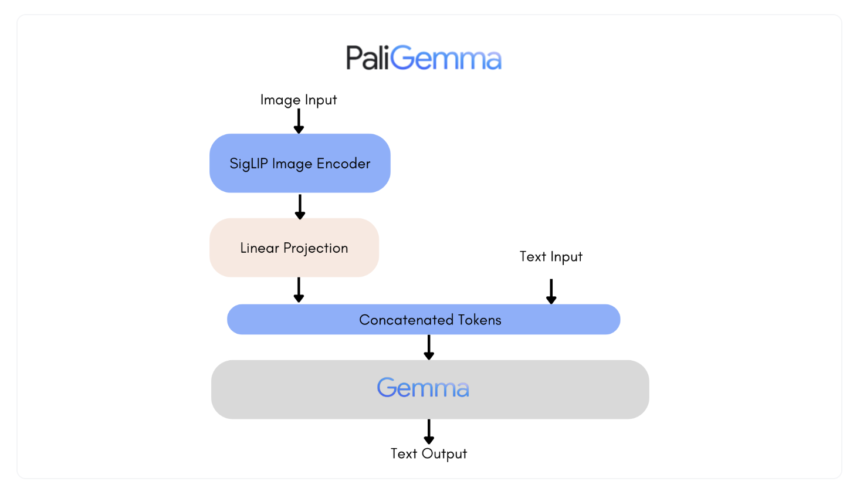
Google has released a new family of vision language models called PaliGemma. PaliGemma can produce text by receiving an image and text input. The architecture of the PaliGemma (Github) family of vision language models consists of the SigLIP-So400m image encoder and the Gemma-2B text decoder. A state-of-the-art model that can understand both text and visuals is called SigLIP. It includes a jointly trained image and text encoder, similar to CLIP. Like PaLI-3, the combined PaliGemma model can be easily fine-tuned on downstream tasks such as captioning or SEO segmentation after being pre-trained on image-to-text data. Gemma is a text generation model that requires a decoder. By using a linear adapter to integrate Gemma with SigLIP's image encoder, PaliGemma becomes a powerful vision language model.
Big_vision was used as the training codebase for PaliGemma. Using the same code base, many other models, including CapPa, SigLIP, LiT, BiT and the original ViT, have already been developed.
The PaliGemma version includes three distinct model types, each offering a unique set of features:
- PT Checkpoints: These pre-trained models are highly adaptable and designed to excel at a variety of tasks. Mixed checkpoints: PT models adjusted for a variety of tasks. They can only be used for research purposes and are suitable for general inferences with free text prompts.
- FT Checkpoints: A collection of refined templates focused on a distinct academic standard. They are intended for research purposes only and come in different resolutions.
The models are available in three distinct precision levels (bfloat16, float16 and float32) and three different resolution levels (224×224, 448×448 and 896×896). Each repository contains the checkpoints for a certain job and a certain resolution, with three revisions for each possible precision. The main branch of each repository has float32 checkpoints, while the bfloat16 and float16 revisions have corresponding precisions. It is important to note that models compatible with the original JAX implementation and Hugging Face transformers have different benchmarks.
High-resolution models, while offering higher quality, require significantly more memory due to their longer input sequences. This might be a consideration for users with limited resources. However, the quality gain is negligible for most tasks, making the 224 versions a suitable choice for the majority of uses.
PaliGemma is a single-turn visual language model that works best when tailored to a particular use case. It is not intended for conversational use. This means that while it excels at specific tasks, it may not be the best choice for all applications.
Users can specify the task the model will perform by qualifying it with task prefixes such as “detect” or “segment”. This is because the pre-trained models have been trained in a way that gives them a wide range of skills, such as question answering, captioning, and segmentation. However, instead of being used immediately, they are designed to be tailored to specific tasks using a comparable prompt structure. The “mix” family of models, fine-tuned on various tasks, can be used for interactive testing.
Here are some examples of what PaliGemma can do: it can add captions to images, answer questions about images, detect entities in images, segment entities in images, and reason and understand documents. These are just a few of its many abilities.
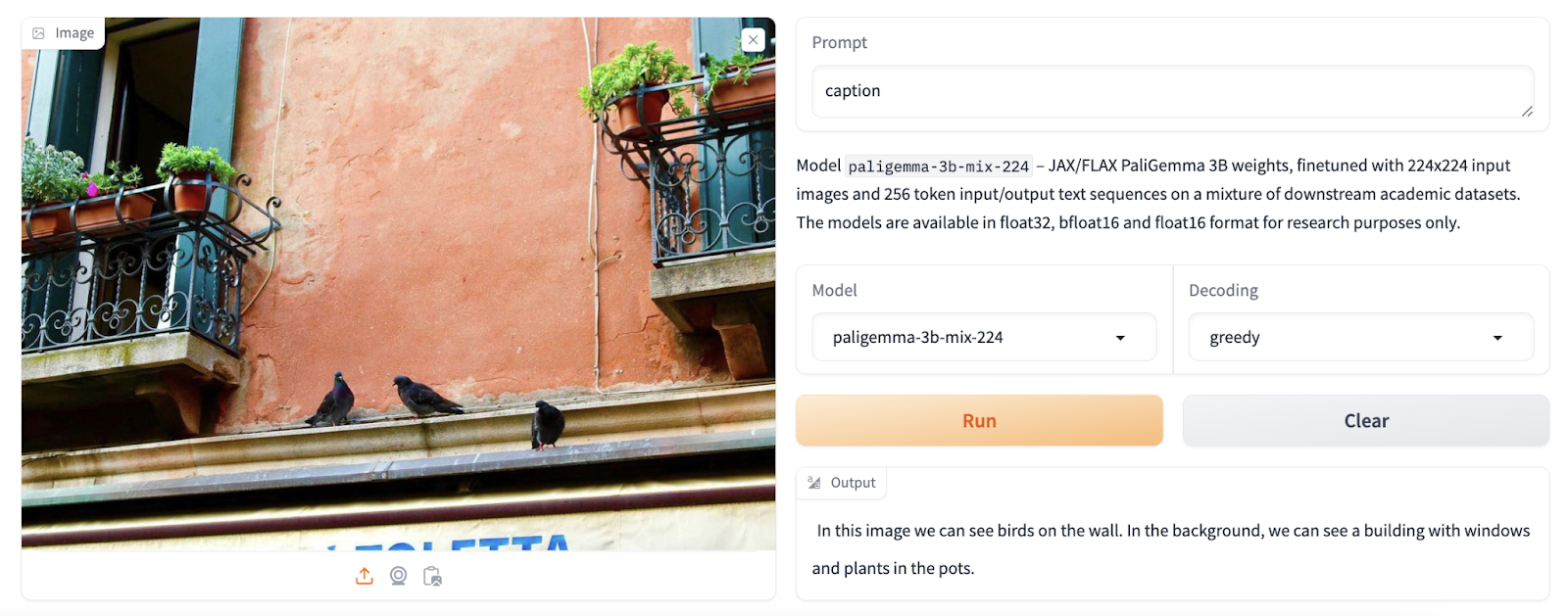
- When asked, PaliGemma can add captions to images. With Mix Checkpoints, users can experiment with different captioning prompts to see how they react.
- PaliGemma can answer a question about an image transmitted with it.
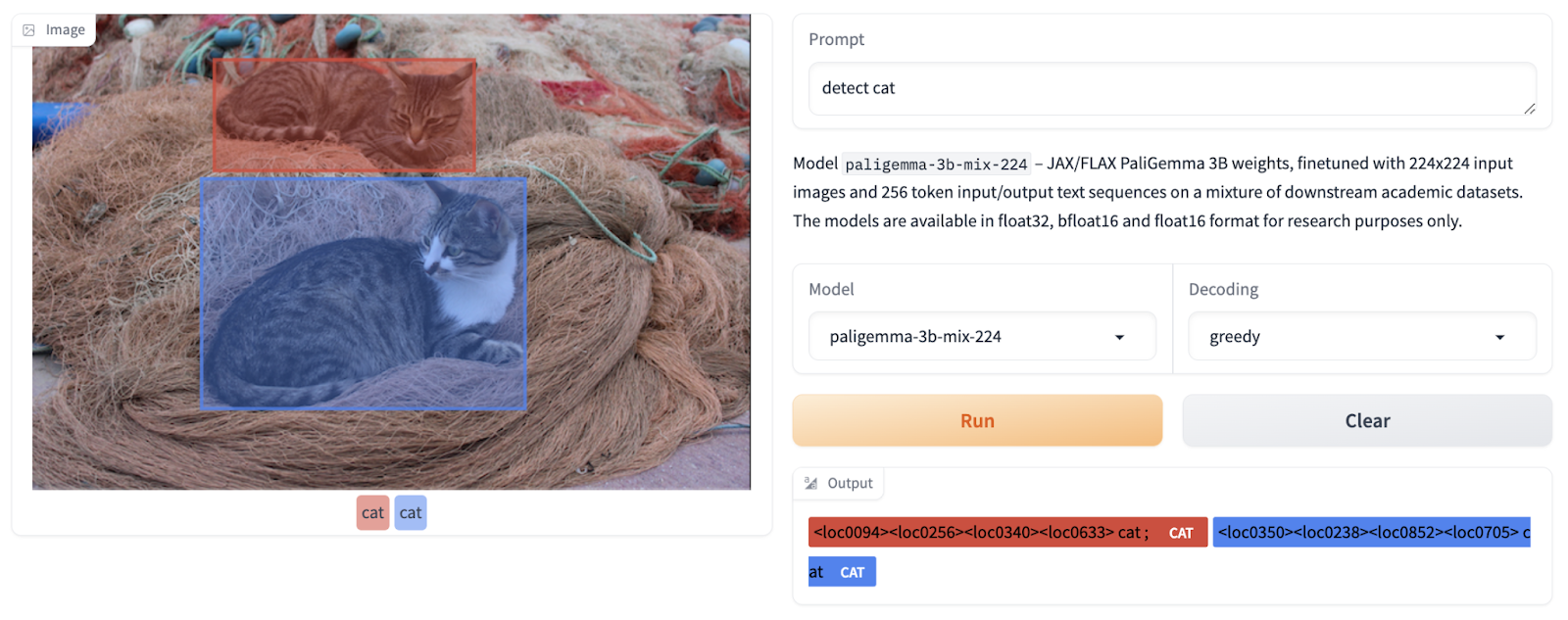
- PaliGemma can use the detect (entity) prompt to search for entities in an image. The location of the bounding box coordinates will be printed as single tokens, where the value is an integer that denotes a normalized coordinate.

- When prompted by the segment (feature) prompt, PaliGemma mix control points can also segment features within an image. Since the team uses natural language descriptions to refer to items of interest, this technique is known as referencing phrase segmentation. The result is a series of segmentation and location tokens. As mentioned earlier, a bounding box is represented by the location tokens. Segmentation masks can be created by reprocessing the segmentation tokens.

- PaliGemma mix checkpoints are very effective for reasoning and understanding documents.
he field.
Check Blog, ModelAnd Demo. All credit for this research goes to the researchers of this project. Also don't forget to follow us on Twitter. Join our Telegram channel, Discord ChannelAnd LinkedIn Groops.
If you like our work, you will love our bulletin..
Don't forget to join our 42,000+ ML subreddit
Dhanshree Shenwai is a Computer Science Engineer with good experience in FinTech companies spanning Finance, Cards & Payments and Banking with a keen interest in AI applications. She is enthusiastic about exploring new technologies and advancements in today's changing world that makes everyone's life easier.