

Plant breeding is essential to ensure a stable diet for a growing global population. To effectively meet growing food demand, plant breeding must achieve high rates of genetic gain. Genomic selection is a powerful tool, leveraging genome-wide DNA variation and phenotypic data to predict the performance of unobserved individuals. Empirical studies have demonstrated the superiority of GS over conventional methods, improving breeding gains and reducing breeding cycles in various crops. Additionally, deep learning techniques, a subset of artificial intelligence, are increasingly being explored in genomic prediction, which shows promise for improving prediction accuracy, especially with the increasing volume of data. genetics. This intersection of genomics and DL could potentially revolutionize various fields, including precision medicine and agriculture.
Deep learning architectures: a genomics perspective:
Recent advances in deep genomic learning architectures have enabled more efficient and accurate processing of biological data. CNNs excel at capturing genomic patterns, while RNNs handle sequential data like DNA sequences. Autoencoders, including variational autoencoders (VAE), are useful for feature extraction and dimensionality reduction. Emerging architectures, such as hybrid models combining CNN and RNN, effectively tackle specific genomic tasks. Transformer-based LLMs, such as GPT, overcome the limitations of CNNs and RNNs by efficiently processing long sequences and capturing global dependencies. However, the high cost of training and servicing LLMs remains a challenge, especially for genomics tasks requiring extensive data and privacy concerns.
Genomic applications:
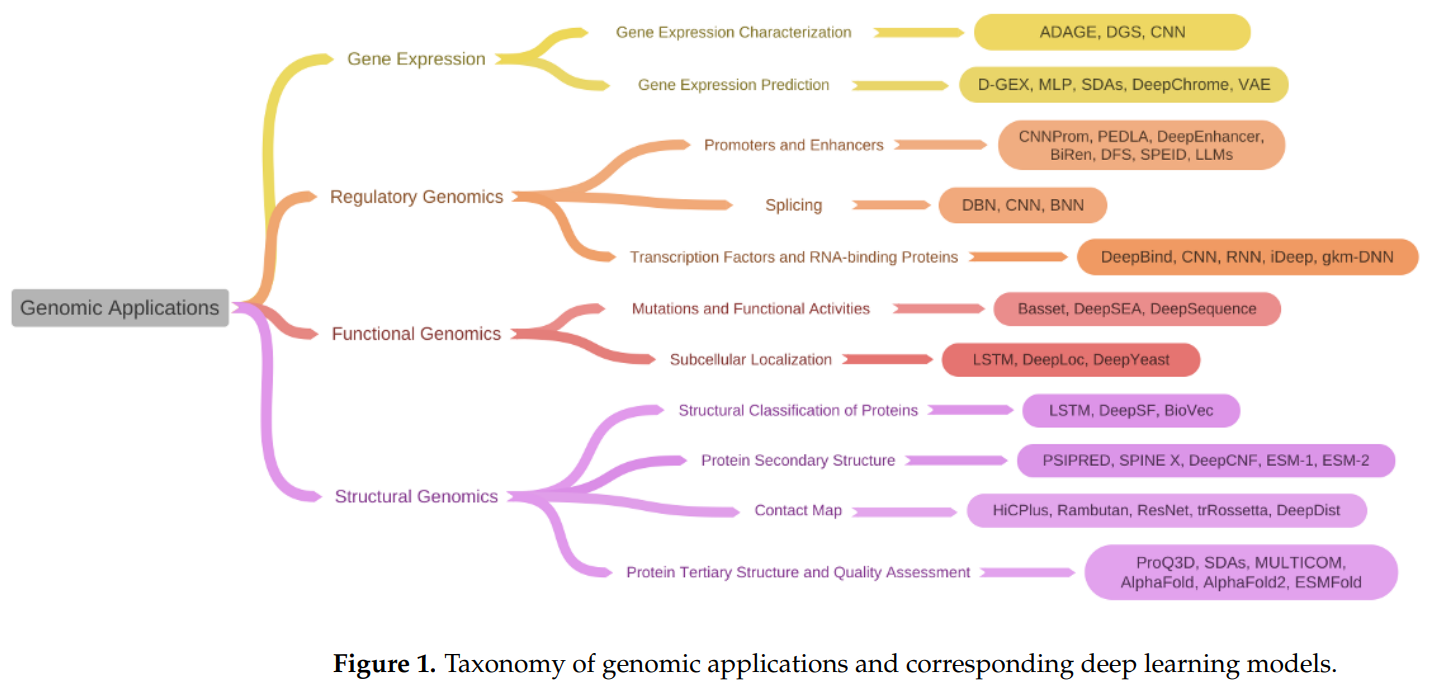
Deep learning is a powerful tool in various genomics applications, including characterization of gene expression, regulatory genomics, functional genomics, and structural genomics. In gene expression characterization, deep learning models such as denoising autoencoders and variational autoencoders have been used to extract features from gene expression data, leading to an understanding of biological processes. and better performance in tasks such as clustering and prediction. Additionally, deep learning methods have shown promise for predicting gene expression levels from DNA sequences, incorporating epigenetic data for increased accuracy and even using generative models to explore profiles of hypothetical gene expression under different perturbations.
In regulatory genomics, deep learning techniques have been applied to identify regulatory motifs such as promoters, enhancers and splice sites, with CNNs being particularly effective at capturing sequence features. Predicting subcellular localization of proteins has also benefited from deep learning, with models such as CNNs and RNNs achieving high accuracy through efficient learning of biological sequence data. Additionally, deep learning methods in structural genomics have shown promise in protein structure classification and homology detection, leveraging techniques such as LSTM networks and CNNs to extract features from amino acid sequences and accurately classify protein folds. Overall, deep learning is revolutionizing genomics research by providing powerful tools to analyze complex biological data and uncover new insights into genetic mechanisms.
Materials and methods:
The study used two datasets from the 1000 Genomes Project, including 10,000 and 65,535 single nucleotide polymorphisms (SNPs) on specific chromosomal regions. They trained generative models including Wasserstein GAN with gradient penalty (WGAN-GP), restricted Boltzmann machines (RBM), and variational autoencoders (VAE) to generate artificial genomic sequences. WGAN-GP and VAE were implemented with convolutional layers, while RBM used nonequilibrium learning. The evaluation included evaluating the models' ability to mimic real data via PCA and calculating adversarial nearest neighbor accuracy (AATS) to measure overfitting and underfitting. Privacy leaks were quantified using a privacy score calculated from the AATS values of the testing and training datasets.
Generate genomic data at scale:
The study trained WGAN and CRBM models on 1,000 genomic data containing 65,535 SNPs to generate artificial genome sequences. Although the VAE model could not be trained effectively, WGAN and CRBM generated sequences that well captured the true population structure and allele frequencies. However, sequences generated by WGAN had more fixed alleles at low frequencies than CRBM. LD decay analysis showed that both models had lower LD than the real genomes. CRBM outperformed WGAN in 3-point correlation analysis, but showed anomalies in AATS values, potentially indicating sequences outside the actual data space. Further analysis revealed higher frequencies of chains of real data points compared to synthetic data points.
Conclusion:
Deep learning shows promise in genomics research due to its ability to capture nonlinear patterns and integrate diverse data sources without explicit feature engineering. However, its superiority over conventional models in terms of predictive power is not yet definitive. Although generative neural networks can effectively simulate large-scale genomic data, challenges such as computational complexity and model optimization persist. Privacy issues also require further investigation. Despite these obstacles, advances in model training and privacy could lead to artificial genome banks, expanding access to genomic data. Deep learning has the potential to revolutionize genomics, but requires a careful approach to the challenges to achieve significant advances in predictive accuracy and interoperability.
Sources:
Sana Hassan, Consulting Intern at Marktechpost and a dual degree student at IIT Madras, is passionate about applying technology and AI to address real-world challenges. With a keen interest in solving practical problems, he brings a fresh perspective to the intersection of AI and real-world solutions.







