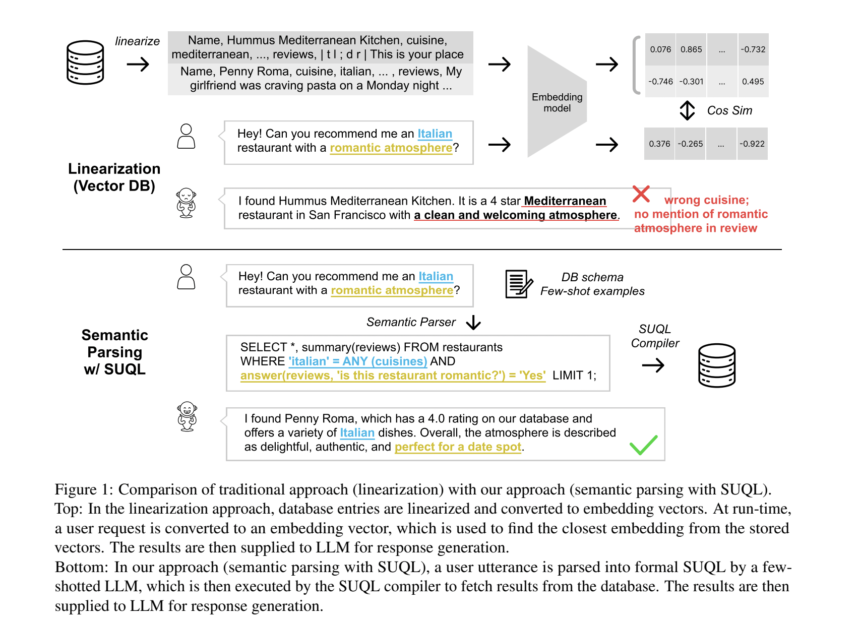
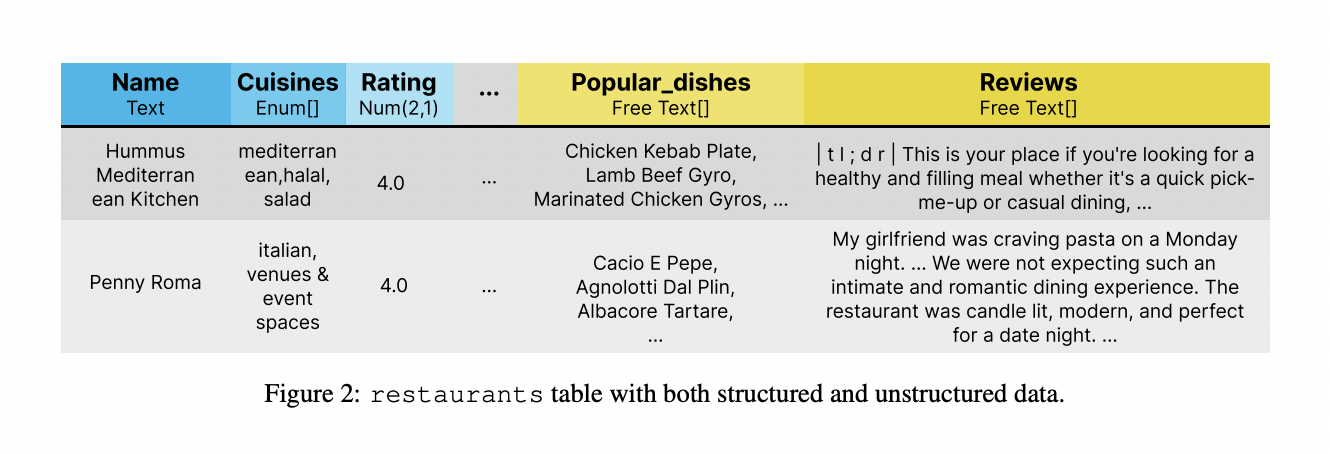
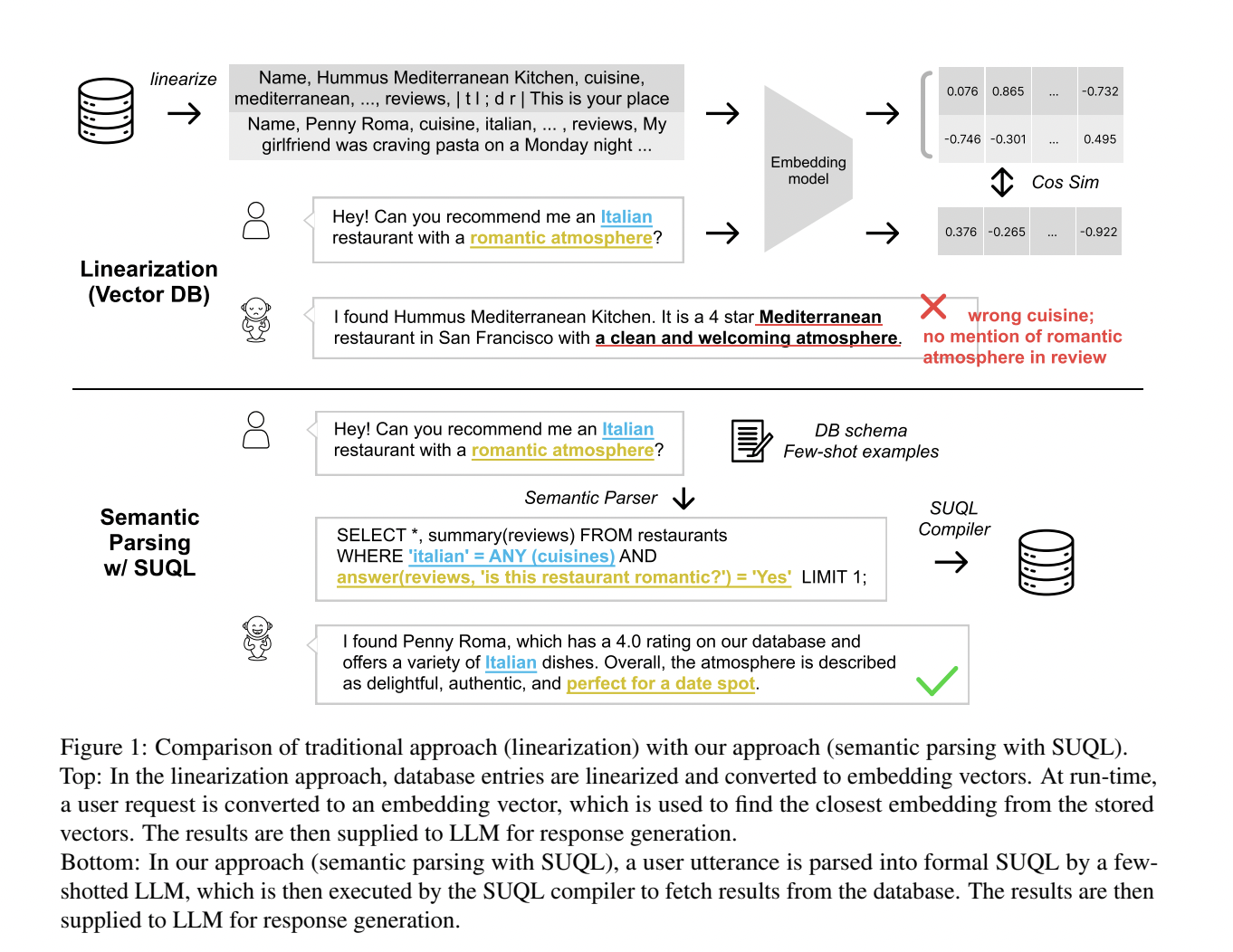
Large language models (LLMs) have gained ground due to their exceptional performance in various tasks. Recent research aims to improve their factuality by integrating external resources, including structured data and free text. However, many data sources, such as patient records and financial databases, contain a mixture of both types of information. “Can you find me an Italian restaurant with a romantic atmosphere?” “, an agent must combine structured attribute cuisines and free text attribute reviews.
Previous chat systems typically use classifiers to direct queries to specialized modules to handle structured data, unstructured data, or chatter. However, this method does not answer questions requiring both structured data and free text data. Another approach is to convert structured data to free text, thereby limiting the use of SQL for database queries and the effectiveness of free text fetchers. The need for hybrid data queries is highlighted by datasets like HybridQA, containing questions requiring information from both structured and open text sources. Previous attempts to anchor Q&A systems on hybrid data operate on small data sets, sacrifice the richness of structured data queries, or support limited combinations of structured and unstructured knowledge queries.
Stanford researchers present an approach for anchoring chatbots in hybrid data sources, using both structured data queries and free text retrieval techniques. It empirically demonstrates that users frequently ask questions involving both structured and unstructured data in real-world conversations, with over 49% of queries requiring knowledge of both types. To gain in expressiveness and precision, they offer SUQL (Structured and Unstructured Query Language)a formal language augmenting SQL with primitives for free text processing, enabling a combination of ready-to-use retrieval models and LLMs with SQL semantics and operators.
The design of the SUQL aims to expressiveness, precision and efficiency. SUQL extends SQL with NLP operators such as SUMMARY and ANSWER, facilitating full-spectrum queries across hybrid knowledge sources. LLMs efficiently translate complex text into SQL queries, allowing SUQL to answer complex queries. Although SUQL queries can run on standard SQL compilers, a naive implementation may be inefficient. Describe the free text primitives of SUQL, highlighting its distinction from retrieval-based methods by expressing queries exhaustively.
The researchers evaluate SUQL through two experiments: one on HybridQA, a question-and-answer dataset, and another on real restaurant data from Yelp.com. The HybridQA experiment uses LLM and SUQL to achieve an exact match (EM) score of 59.3% and an F1 score of 68.3%. SUQL outperforms existing models by 8.9% EM and 7.1% F1 on the test set. In real-world restaurant experiments, SUQL demonstrates turn accuracy of 93.8% and 90.3% in single-turn and conversational queries respectively, outperforming linearization-based methods by up to 36.8% and 26 .9%.
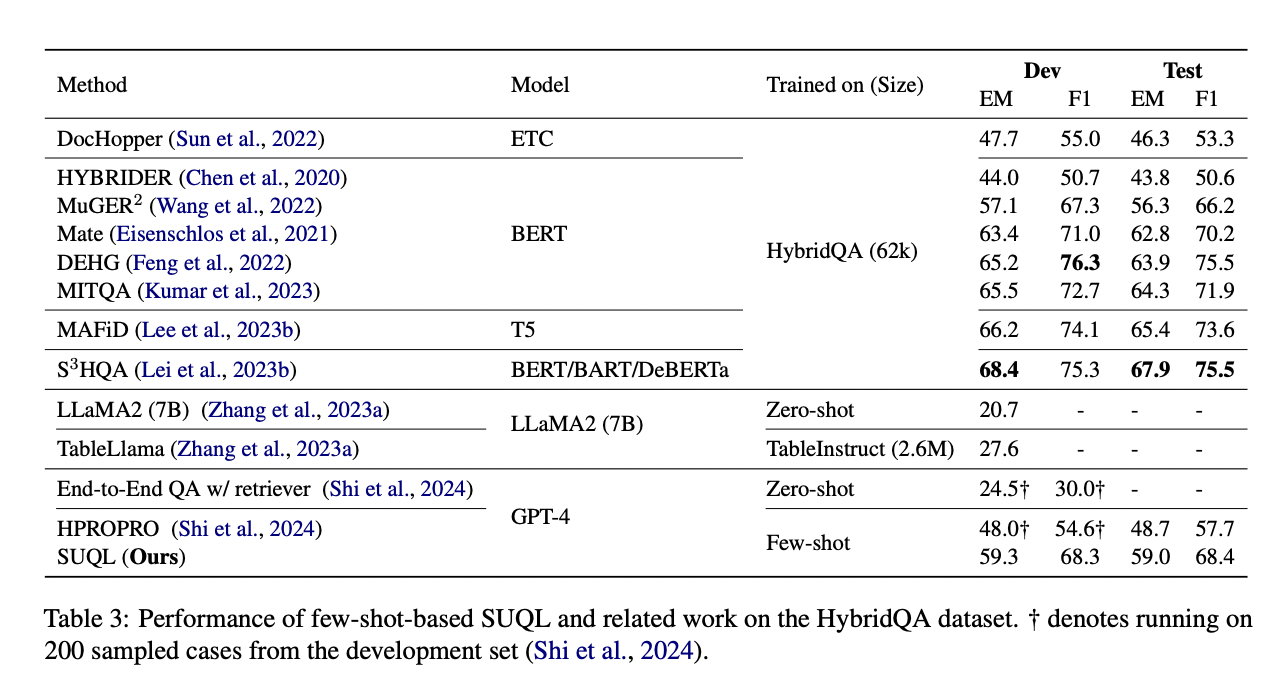
To conclude, this article presents SUQL as the first formal query language for hybrid bodies of knowledge, encompassing structured and unstructured data. Its innovation lies in the integration of free text primitives into a precise and succinct query framework. In-context learning applied to HybridQA achieves results within 8.9% of SOTA, which can be trained on 62,000 samples. Unlike previous methods, SUQL supports large databases and free-text corpora. Experiments on Yelp data demonstrate the effectiveness of SUQL, with a 90.3% success rate in satisfying user queries, compared to 63.4% for the linearization baselines.
Check Paper, GitHubAnd Demo. All credit for this research goes to the researchers of this project. Also don’t forget to follow us on Twitter. Join our Telegram channel, Discord ChannelAnd LinkedIn Groops.
If you like our work, you will love our bulletin..
Don't forget to join our 41,000+ ML subreddit
Asjad is a trainee consultant at Marktechpost. He is pursuing B.Tech in Mechanical Engineering from Indian Institute of Technology, Kharagpur. Asjad is a machine learning and deep learning enthusiast who is always researching the applications of machine learning in healthcare.